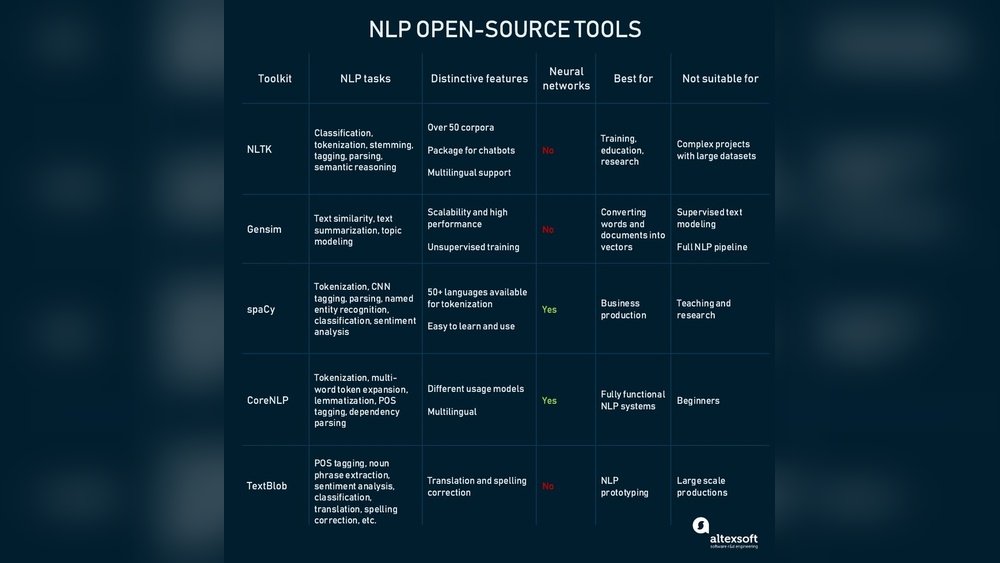
Are you looking to unlock meaningful insights from mountains of text without getting lost in complex coding? The Stanford Open Information Extraction project offers you a powerful, open-source tool that pulls out key relationships and facts straight from plain sentences.
Imagine turning any text into clear, structured information effortlessly—whether you’re analyzing news articles, research papers, or social media posts. You’ll discover how this cutting-edge text processing project can transform your data work, streamline your research, and open new doors for innovation.
Ready to see how it works and why it matters for you? Let’s dive in.
Stanford Openie Basics
The Stanford Open Information Extraction (OpenIE) project offers powerful tools to break down text. It extracts simple facts from complex sentences. This section explains the basic ideas behind Stanford OpenIE. Understanding these basics helps users see how OpenIE fits in natural language processing (NLP).
It works by pulling out key pieces of information from any text. This allows computers to understand and use language more effectively. The following subsections explain what open information extraction is, how relation triples work, and why OpenIE matters in NLP.
What Is Open Information Extraction
Open Information Extraction, or OpenIE, is a method to extract facts from text. It does not rely on predefined rules or specific data sets. Instead, it works on any topic and any sentence. This makes OpenIE flexible and widely useful. OpenIE identifies important parts of a sentence and extracts them as simple data.
For example, from the sentence “Cats play with yarn,” OpenIE pulls out the fact that “cats” are doing the action “play with” on “yarn.” This fact can be used in databases or for further analysis. OpenIE helps convert unstructured text into structured data.
Relation Triples Explained
Relation triples are the building blocks of OpenIE. Each triple has three parts: subject, relation, and object. The subject is the main noun or noun phrase. The relation is the action or link between the subject and object. The object is the entity affected by the relation.
Taking the earlier example, “Cats play with yarn,” the triple is (cats; play with; yarn). This simple format allows machines to understand who did what to whom. Relation triples make it easier to search, compare, and analyze information from text.
Openie’s Role In Nlp
OpenIE plays a key role in many NLP tasks. It helps machines extract facts without needing complex training. This speeds up tasks like question answering and knowledge base creation. OpenIE supports automatic summarization by highlighting key information.
It also helps in detecting relationships in large text collections. This is useful for research, business intelligence, and more. Stanford OpenIE provides a reliable way to turn text into data that computers can use easily.
Key Features
The Stanford Open Information Extraction project offers powerful tools for text analysis. It focuses on extracting meaningful information from text automatically. Its key features make it stand out for developers and researchers alike.
This system can handle various types of text inputs with ease. It works well with complex sentences and integrates smoothly with other language tools. These features enhance its accuracy and usability in many applications.
Open-domain Extraction
The project extracts relations from any text topic without predefining categories. It finds subject, relation, and object triples automatically. This open-domain approach allows it to work on broad data sets.
Users do not need to train it on specific topics. It can process news, social media, or scientific papers equally well. This flexibility makes it useful for many real-world tasks.
Handling Complex Sentences
The system understands sentences with multiple clauses or tricky structures. It breaks down long sentences into simpler parts. This helps extract accurate information from complicated text.
It detects nested relations and connects ideas clearly. The ability to parse complex sentences improves the quality of extracted data. This feature supports deeper text understanding.
Integration With Stanford Corenlp
Stanford OpenIE works closely with Stanford CoreNLP tools. It uses CoreNLP for tasks like tokenization, parsing, and part-of-speech tagging. This integration ensures high-quality language processing.
The combined system provides a full pipeline for text analysis. Users benefit from reliable and fast extraction results. The smooth integration simplifies workflow for developers.
Technical Architecture
The technical architecture of the Stanford Open Information Extraction project forms the backbone of its powerful text processing capabilities. It is designed to handle vast amounts of unstructured text and extract meaningful relationships efficiently. The system breaks down complex text into simpler components for easier analysis.
At its core, the architecture relies on a well-defined pipeline and an algorithmic approach to process and extract data. This structure ensures flexibility and scalability, allowing the tool to adapt to different text types and domains. Understanding the key parts of this architecture helps in appreciating how the tool extracts clear and structured information from raw text.
Pipeline Components
The pipeline consists of several key components working together. It starts with sentence splitting, breaking text into manageable pieces. Next, part-of-speech tagging assigns word types like nouns or verbs. Then, dependency parsing builds a tree structure showing word relationships.
After parsing, the system applies pattern matching to find potential relation triples. Finally, it filters and ranks these triples to keep the most relevant ones. Each stage refines the data and prepares it for the next step, ensuring accurate extraction.
Algorithmic Approach
The project uses a rule-based algorithm combined with statistical models. It relies on syntactic patterns in sentences to identify relations. These patterns match how subjects, verbs, and objects typically appear together.
The algorithm evaluates each candidate relation triple for grammatical correctness. It also scores triples based on confidence levels from training data. This method balances precision and recall, improving extraction quality without missing important relations.
Data Processing Workflow
The workflow begins by feeding raw text into the system. The pipeline components process the text step-by-step. At each step, the system adds structure and meaning to the data.
Extracted triples are stored in a structured format for easy access. Users can then query or analyze these triples for various applications. This workflow supports continuous updates and scaling for large datasets.

Credit: kili-technology.com
Applications In Data Extraction
The Stanford Open Information Extraction (OpenIE) project is a valuable tool for data extraction. It processes natural language text to pull out meaningful information. This technology helps transform unstructured text into structured data. Such data plays a key role in many fields.
Below are some common applications of Stanford OpenIE in data extraction tasks.
Knowledge Graph Construction
Stanford OpenIE extracts relation triples from text, such as subject, relation, and object. These triples help build knowledge graphs that link entities and their relationships. Knowledge graphs support better understanding of concepts and facts. They are useful in areas like recommendation systems and semantic search. OpenIE simplifies gathering accurate connections from large text sources.
Text Mining And Analysis
OpenIE enables efficient text mining by capturing key relationships automatically. Analysts use these extracted triples to spot trends, patterns, and key themes in documents. It speeds up processing of news articles, reports, and social media content. This approach reduces manual work and improves data quality. The extracted data supports sentiment analysis, topic detection, and event identification.
Enhancing Search And Retrieval
Search systems benefit from OpenIE by indexing extracted relations instead of just keywords. This leads to more precise and context-aware search results. Users can find information based on entity relations and facts rather than simple matches. OpenIE helps create smarter search engines that understand natural language queries better. This improves user experience and saves time during information retrieval.
Open Source Benefits
The Stanford Open Information Extraction project thrives as an open source initiative. Open source software offers many benefits that speed up innovation and improve quality. It allows users and developers to work together in a shared space. This cooperation leads to faster problem solving and better software tools.
Open source also gives users control over the software. They can change it to fit their needs exactly. This flexibility is rare in closed, proprietary software.
Community Contributions
Many people worldwide add to the project. Each contributor brings new ideas and fixes bugs. This shared effort keeps the software reliable and up to date. Users also share how they use the tool, creating helpful guides and examples. The community acts as a support network for everyone involved.
Customization And Flexibility
Users can modify the software freely. They adjust it to handle specific text or domains. This makes the tool useful across many fields. Custom versions help solve unique problems that one-size-fits-all software cannot address. Flexibility lets organizations integrate the project into their own systems.
Transparency And Trust
Open source code is visible to all. Anyone can inspect how the software works. This openness builds trust in the tool’s accuracy. Users feel confident because they can verify the code themselves. Transparency helps prevent hidden errors or malicious features.
Comparisons With Other Tools
Stanford Open Information Extraction (OpenIE) stands out in a crowded field of text processing tools. Comparing it with other solutions highlights its unique strengths and practical uses. This section breaks down these differences clearly.
Stanford Openie Vs Traditional Ie
Traditional Information Extraction (IE) tools rely on predefined schemas. They need manual setup for specific domains. Stanford OpenIE extracts relations without prior knowledge. It works on open domains, making it flexible. This flexibility helps handle diverse and new texts. Traditional IE often misses unknown relations. OpenIE captures a wide range of relations automatically. It reduces the need for costly and slow manual tuning.
Advantages Over Closed Source Solutions
Closed source tools limit transparency and adaptability. Stanford OpenIE is open source and fully accessible. Developers can review and improve its code. This openness encourages community contributions and updates. Users avoid vendor lock-in with OpenIE. It adapts to various research or business needs. Closed solutions might hide errors or biases. OpenIE offers clear, inspectable processing steps. It provides trust and control over data processing.
Complementary Nlp Tools
Stanford OpenIE works well with other NLP tools. It complements Named Entity Recognition (NER) and coreference resolution. These tools together improve text understanding and extraction quality. OpenIE triples can feed into knowledge graphs or question answering systems. The Stanford NLP suite offers smooth integration among its tools. Combining these tools creates powerful pipelines. This boosts accuracy in complex text analysis tasks. Users gain a modular, flexible approach to natural language processing.
Getting Started With Stanford Openie
Getting started with Stanford Open Information Extraction (OpenIE) is easier than many expect. This tool helps pull useful information from plain text by extracting relation triples. These triples show connections between words, making data more organized and ready for analysis.
Stanford OpenIE works well for those who want to explore natural language processing without deep technical skills. It supports various programming languages and offers clear examples to jumpstart your projects. Follow the steps below to install, use, and integrate OpenIE into your Python workflow.
Installation And Setup
First, download the Stanford OpenIE package from the official Stanford NLP website. The tool requires Java to run, so ensure Java Runtime Environment is installed on your computer.
Unzip the package to a convenient folder. Open a terminal or command prompt and navigate to this folder. Run the command java -mx4g -cp "" edu.stanford.nlp.naturalli.OpenIE to start the server.
Check the server is running by visiting http://localhost:9000 in your web browser. You can now send text inputs to the server for extraction.
Basic Usage Examples
OpenIE extracts triples like (subject; relation; object) from sentences. For example, the sentence “Cats play with yarn” yields (Cats; play with; yarn).
Try a simple command line call: echo "Stanford University is located in California." | java -mx4g -cp "" edu.stanford.nlp.naturalli.OpenIE. This command outputs triples showing the main relations.
These triples help understand sentence structure and meaning. You can use them for data analysis or building knowledge graphs.
Python Integration Tips
Use Python wrappers like stanford-openie-py for easier access. Install it via pip with pip install stanford-openie.
After installation, start the OpenIE server as described earlier. Then write Python code to connect to the server and send text for extraction.
Example code snippet:
from stanford_openie import StanfordOpenIE with StanfordOpenIE() as client: text = "Barack Obama was born in Hawaii." triples = client.annotate(text) for triple in triples: print(triple) This approach helps include OpenIE in larger Python projects. It supports batch processing and easy result handling.

Credit: www.techmagic.co
Challenges And Limitations
The Stanford Open Information Extraction project offers powerful tools for text processing. Despite its strengths, this open-source project faces several challenges and limitations. These issues affect how well it extracts meaningful information from text. Understanding these challenges helps improve the tool’s future development.
Handling Ambiguity
Natural language often contains words with multiple meanings. Stanford OpenIE can struggle to decide which meaning fits best. This ambiguity leads to incorrect or unclear extractions. The system might confuse subjects or actions in complex sentences. Resolving ambiguity remains a key challenge for accurate information extraction.
Scalability Concerns
Processing large amounts of text requires significant computing power. Stanford OpenIE can slow down with very big datasets. Scaling the system to handle massive documents is not easy. Performance may drop, causing delays and less reliable outputs. Finding ways to optimize speed and resource use is crucial for scalability.
Improving Extraction Accuracy
Extracting precise relations from diverse texts is difficult. Errors can occur in detecting entities and their connections. The system sometimes misses important details or adds wrong information. Enhancing accuracy needs better algorithms and more training data. Continuous improvements help make extractions more reliable and useful.
Future Developments
The future of the Stanford Open Information Extraction project promises exciting improvements. These advancements aim to make text processing smarter and more flexible. The focus will be on making the tool better at understanding language and extracting information with higher accuracy. Researchers plan to enhance the system’s ability to handle diverse languages and complex contexts. These steps will expand the project’s reach and usefulness for many users worldwide.
Neural Openie Advances
Neural networks will play a bigger role in future versions. These models can learn from large amounts of data. They help the system find relations in text more accurately. Neural OpenIE will improve the extraction of complex information. It will better handle ambiguous or unclear sentences. This will lead to more reliable and detailed outputs.
Expanding Language Support
The project will support more languages beyond English. This is important for global use and research. Adding new languages requires adapting models to different grammar and structures. The team will work on this to make the tool accessible worldwide. Users will benefit from OpenIE’s ability to process texts in many languages. This expansion will open doors for more diverse applications.
Enhanced Contextual Understanding
Future updates will focus on deeper context awareness. The system will better understand the meaning behind sentences. It will recognize nuances and subtle language cues. This helps in extracting more accurate and relevant information. Enhanced context understanding reduces errors in relation extraction. It also improves the overall quality of the extracted data.

Credit: devopedia.org
Frequently Asked Questions
Is Stanford Nlp Open Source?
Yes, Stanford NLP offers open-source tools like Stanford CoreNLP and Stanford OpenIE, available for public use and development.
What Is Nlp Extraction?
NLP extraction identifies key data like names, events, and relationships from text. It converts unstructured text into structured information for analysis and use.
What Is Openie?
OpenIE extracts structured relation triples, like subject, relation, and object, directly from plain text. It enables open-domain information extraction for various NLP applications.
What Is Stanford Ner?
Stanford NER is a Java tool that identifies and labels named entities like persons, companies, and genes in text.
What Is Stanford Open Information Extraction (openie)?
Stanford OpenIE is a tool that extracts relation triples from plain text. It identifies subjects, relations, and objects without needing a fixed schema. This helps understand text meaning easily.
Conclusion
Stanford Open Information Extraction helps turn text into clear data. It finds important facts and relations in simple sentences. This open source tool supports many language projects and research. Anyone can use it to analyze text quickly and easily. It makes understanding written content faster and smarter.
OpenIE from Stanford continues to improve natural language processing tools. Explore its features to boost your text analysis skills today.