If you work with text data, you know how important it is to understand the role each word plays in a sentence. That’s where the Stanford Log Linear Part of Speech Tagger steps in.
This powerful, open source tool automatically labels every word with its correct part of speech—whether it’s a noun, verb, adjective, or something else. Imagine how much easier your text processing tasks could become with accurate tagging right at your fingertips.
You’ll discover what makes the Stanford Tagger a standout choice for developers and researchers alike, how it works, and why it could be the key to unlocking deeper insights from your text data. Stick around—you won’t want to miss how this tool can transform your projects.

Credit: spotintelligence.com
Stanford Log-linear Pos Tagger Basics
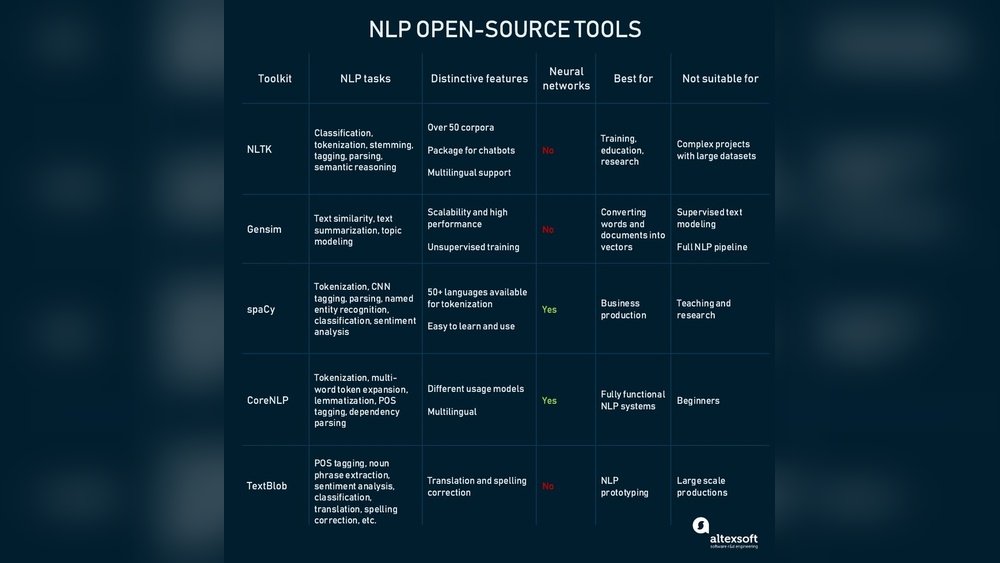
The Stanford Log-Linear Part of Speech (POS) Tagger is a key tool in text processing. It reads text and assigns parts of speech to each word. This process helps computers understand language structure. The tagger uses a statistical model called log-linear modeling. It improves accuracy in tagging words correctly in context.
This tagger is widely used in natural language processing tasks. It works efficiently on large text datasets. Its design balances speed and accuracy. Developers and researchers rely on it for various language projects.
Core Features
The tagger uses a log-linear model for tagging. It considers the context around each word. This method helps it handle ambiguous words well. The system supports multiple tagging schemes. It also allows training on custom datasets. Users get detailed part of speech tags. The tagger runs quickly even on large texts. It integrates easily with Java applications.
Supported Languages
The Stanford Log-Linear POS Tagger supports several languages. English is the primary language with high accuracy. Other languages include Chinese, Spanish, and German. Users can train the tagger on new languages. This flexibility expands its usability worldwide. Language-specific models improve tagging precision. The tagger adapts to different grammar rules easily.
Open Source Philosophy
The tagger is fully open source. This means anyone can access and modify the code. It encourages collaboration among developers and researchers. Open source status promotes transparency in development. Users can customize the tool for their needs. The community shares improvements and fixes regularly. This approach helps the tagger stay up to date. Open source software also lowers barriers to use.
Credit: www.nature.com
Architecture And Technology
The architecture and technology behind the Stanford Log Linear Part of Speech Tagger make it a reliable tool for text processing. It uses advanced statistical models to assign parts of speech to words in a sentence. The design focuses on accuracy and efficiency, which helps in understanding natural language.
This tagger is built on a strong foundation of machine learning principles. It analyzes text by considering the context of each word. This approach improves the precision of tagging compared to simple rule-based systems.
Log-linear Model Explained
The core technology is the log-linear model. This model predicts the part of speech by combining different features of the text. It assigns weights to these features based on their importance. The model then calculates probabilities for each possible tag and selects the most likely one.
This method allows the tagger to handle complex language patterns. It can adapt to various languages and styles by updating the feature weights. The log-linear model balances simplicity and power in processing language data.
Statistical Methods Used
The tagger applies statistical methods to learn from data. It uses maximum entropy principles to estimate the best tag for each word. The system considers the surrounding words to improve accuracy. This context-aware technique helps resolve ambiguities in language.
Training involves large datasets with labeled parts of speech. The tagger adjusts its parameters to minimize errors. This statistical learning ensures better predictions on new, unseen text.
Pretrained Models
The Stanford Tagger offers pretrained models for quick use. These models are trained on extensive text corpora. Users can apply them directly without deep knowledge of machine learning.
Pretrained models save time and resources. They provide strong baseline performance for many languages. Users can also fine-tune these models for specific needs or domains.
Installation And Setup
Setting up the Stanford Log Linear Part of Speech Tagger is straightforward. This open-source tool requires a few steps for installation and integration. It works well on many systems and supports Java and Node.js environments. Follow the instructions to get started quickly and efficiently.
System Requirements
The tagger runs on Java, so Java Runtime Environment (JRE) 8 or higher is necessary. It needs about 200 MB of disk space for the software and models. A minimum of 4 GB RAM is recommended for smooth processing. The tool works on Windows, macOS, and Linux systems. Ensure your system meets these to avoid installation issues.
Step-by-step Installation
First, download the latest version of the tagger from the official Stanford NLP website. Extract the zip file to a folder on your computer. Set the environment variable JAVA_HOME to your Java installation path. Open a command prompt or terminal and test Java by typing java -version. Next, run the tagger using the command line script provided. Check if the tagger loads without errors. This confirms a successful installation.
Integration With Java And Node.js
To use the tagger in Java, add the Stanford NLP jar files to your project’s classpath. Use the provided example code to load and run the tagger on text data. For Node.js, install the stanford-postagger package via npm. Import the package in your JavaScript file and initialize the tagger with the model path. This allows easy tagging of text within your Node.js apps.
Using The Tagger
The Stanford Log Linear Part of Speech Tagger is a powerful tool for text analysis. Using the tagger lets you identify parts of speech in your text quickly and accurately. This section explains how to use the tagger effectively for different needs. It covers basic commands, handling various text formats, and working with markup languages like XML.
Basic Command Line Usage
Run the tagger from the command line for simple tagging tasks. Use the main Java jar file and specify the model. Then provide the input text file and the output file name. The command looks like this:
java -mx300m -cp stanford-postagger.jar edu.stanford.nlp.tagger.maxent.MaxentTagger -model model.tagger -textFile input.txt -outputFormat tsv -outputFile output.txtThis command tags each word with its part of speech and saves the result in a tab-separated file. Adjust memory size (-mx) based on your system. Make sure to use the correct model file for your language.
Tagging Text In Different Formats
The tagger works with plain text but also supports other formats. It can process tokenized text, where words are already separated. The output format can be changed to suit your needs. Options include plain text, tab-separated values, or inline tags.
Specify output format using the -outputFormat option. For example, use inline to get tagged words inside the original text:
-outputFormat inlineThis keeps the text readable while showing part of speech tags directly after each word. Choose the format that best fits your project.
Working With Xml And Other Markup
The tagger can handle XML and similar markup languages. It tags only the text inside the tags and leaves markup untouched. Use the -xmlInput option to enable this feature:
-xmlInput trueThis keeps the XML structure intact while adding part of speech tags to the text. It is useful for processing annotated documents or web data. The tagger skips tags and focuses on the words inside them.
You can also customize which tags to preserve or ignore. This flexibility helps when working with complex XML files or other markup formats. The output remains well-formed XML with added linguistic information.
Customization And Training
The Stanford Log Linear Part of Speech Tagger offers strong options for customization and training. Users can shape the tagger to fit unique needs. This flexibility makes it ideal for diverse text analysis tasks. Training new models, adapting to custom corpora, and fine-tuning parameters are key steps in this process.
Training New Models
Training new models helps the tagger learn from fresh data. Users start with a set of sentences already labeled with parts of speech. The tagger studies these examples to recognize patterns. This process improves accuracy on similar text later. Training can be repeated to include more data or languages. It ensures the tagger stays relevant to specific projects.
Adapting To Custom Corpora
Adapting the tagger to custom corpora is crucial for specialized texts. Different fields use unique vocabulary and grammar. Feeding the tagger with domain-specific text helps it understand these differences. This adaptation reduces errors in tagging uncommon words. It makes the tagger more useful for particular industries or research areas. Custom corpora provide a tailored training ground for better results.
Parameter Tuning
Parameter tuning adjusts the tagger’s settings to boost performance. Users can change aspects like feature sets or regularization strength. These tweaks affect how the tagger learns and predicts tags. Testing different configurations reveals what works best for the task. Proper tuning balances speed and accuracy. It enhances the tagger’s ability to handle complex language patterns effectively.

Credit: spotintelligence.com
Performance And Accuracy
The Stanford Log Linear Part of Speech Tagger delivers strong performance with high accuracy. It efficiently processes large text sets while maintaining speed. This balance makes it a favored tool in many natural language processing tasks. The tagger uses advanced statistical models, which help it assign correct parts of speech to words. This section explores its benchmark results, compares it with other taggers, and explains how it manages ambiguous cases.
Benchmark Results
In standard tests, the Stanford tagger achieves over 97% accuracy. It performs well on various text types, including news and social media. Its processing speed allows tagging thousands of words per second. These results show it works reliably in real-world applications. Continuous updates have helped improve its accuracy over time.
Comparison With Other Pos Taggers
The Stanford tagger stands out for its balance of speed and accuracy. Compared to other popular taggers, it often scores higher in accuracy tests. Some taggers may run faster but lose precision. Others focus on accuracy but slow down processing. The Stanford tool offers a strong middle ground, making it versatile for many users.
Handling Ambiguities
Ambiguous words pose challenges in part-of-speech tagging. The Stanford tagger uses a log-linear model to resolve these. It considers the context around a word to choose the best tag. This approach reduces errors in tricky cases. It also adapts well to new or unusual text patterns. This ability helps maintain high accuracy across varied texts.
Applications And Use Cases
The Stanford Log Linear Part of Speech Tagger serves many practical roles. This tool tags each word in text with its part of speech. Such tagging is vital for many tasks that involve understanding text. The applications span from academic research to real-world business uses. Its flexibility and accuracy make it a popular choice.
Natural Language Processing Pipelines
This tagger is often a key step in NLP pipelines. It helps break down sentences into parts like nouns, verbs, and adjectives. This breakdown allows other tools to analyze sentence structure. It improves tasks like parsing, named entity recognition, and sentiment analysis. Developers use it to build smarter, context-aware applications.
Text Analysis In Research
Researchers use the tagger to study language patterns. It helps analyze large text datasets quickly. Linguists explore how words behave in different contexts. Social scientists track how language changes over time. The tagger supports projects that require detailed text annotation and analysis.
Industry Implementations
Many industries deploy this tagger to enhance their services. In customer support, it helps understand user queries better. Marketing teams analyze consumer feedback to improve campaigns. Healthcare systems process clinical notes to extract key information. The tagger enables automation and improves decision-making across sectors.
Frequently Asked Questions
What Is The Stanford Log Linear Part Of Speech Tagger?
It is open source software that assigns parts of speech to each word in text. It helps computers understand language structure.
How Does The Stanford Pos Tagger Work?
It uses a log-linear model to predict the part of speech for each word. The model is trained on labeled text data.
Which Languages Does The Stanford Pos Tagger Support?
The tagger mainly supports English but can be trained for other languages. Custom training improves tagging accuracy for specific languages.
Can I Use The Stanford Pos Tagger For Xml Files?
Yes, it can process XML by tagging words within the text content. Some setup is needed to handle XML structure properly.
Is The Stanford Log Linear Pos Tagger Free To Use?
Yes, it is free and open source under the GNU license. You can download, modify, and use it without cost.
Conclusion
The Stanford Log Linear Part of Speech Tagger offers clear, reliable text analysis. It helps identify each word’s role in a sentence quickly. This open source tool supports multiple languages for varied projects. Users can integrate it easily into different applications.
It remains a strong choice for text processing needs. Exploring it can improve understanding of language data. Simple, fast, and effective—that sums it up well.