If you work with text data, you know how tricky it can be to extract meaningful information quickly and accurately. That’s where the Open Source Text Processing Project Oleanderstemminglibrary steps in to make your life easier.
Designed to simplify the way you handle word forms and root words, this powerful library offers a smart, efficient approach to stemming—one of the core tasks in natural language processing. Whether you’re building search engines, chatbots, or analyzing massive text datasets, Oleanderstemminglibrary can boost your project’s performance and precision.
Ready to discover how this tool can transform your text processing work? Keep reading to unlock its full potential and learn how to integrate it seamlessly into your workflow.

Credit: github.com
Oleanderstemminglibrary Features
The Oleanderstemminglibrary is a powerful open-source tool designed for text processing. It offers a set of features that make handling and analyzing text data easier. This library focuses on efficient stemming techniques and smooth integration with other software. Its features support developers and researchers in natural language processing tasks.
Core Text Processing Capabilities
Oleanderstemminglibrary provides essential text processing functions. It can tokenize text, breaking it into words or phrases. The library also normalizes text by converting it to lowercase and removing punctuation. These steps prepare text data for further analysis. It supports handling large text datasets quickly and accurately.
Unique Stemming Algorithms
The library includes innovative stemming algorithms. These algorithms reduce words to their root forms. They handle irregular word forms better than traditional stemmers. This improves the accuracy of text analysis and search results. The stemming process is designed to balance precision and speed. Users get reliable results for different languages and domains.
Compatibility And Integration
Oleanderstemminglibrary works well with many programming languages. It offers APIs for easy integration into existing projects. The library supports popular development environments and frameworks. It can be combined with other natural language processing tools. This flexibility allows developers to build complex text applications efficiently.

Credit: github.com
Boosting Efficiency With Oleanderstemminglibrary
Oleanderstemminglibrary improves text processing tasks by making them faster and more efficient. It handles large amounts of text data with ease. Its design focuses on reducing delays and saving computing power. Users can expect smoother workflows and quicker results.
This library is ideal for developers and researchers who need reliable text analysis tools. It streamlines operations without sacrificing accuracy. The code is open source, allowing community improvements and updates. Efficiency gains are clear in real-world applications.
Performance Improvements
Oleanderstemminglibrary processes text data with high speed. It uses optimized algorithms that cut down unnecessary steps. This leads to faster completion of language tasks like stemming and tokenizing. The library works well even on limited hardware.
Its performance stands out in benchmarks compared to similar tools. Users report noticeable boosts in processing rates. This makes it suitable for applications needing quick text analysis. The library balances speed with consistent output quality.
Reducing Processing Time
Processing time drops significantly with Oleanderstemminglibrary. The library minimizes the time needed for each text operation. It avoids redundant calculations and streamlines workflows. This helps projects meet tight deadlines and increase throughput.
Shorter processing times mean faster access to insights from data. Users save hours on large-scale text processing tasks. The efficient code structure directly benefits time-sensitive applications. It allows handling bigger datasets without delays.
Resource Optimization
Oleanderstemminglibrary uses system resources carefully. It reduces memory and CPU usage during text processing. This optimization extends battery life on mobile devices. It also lowers costs for cloud-based deployments.
The library adapts to available hardware, scaling resource use accordingly. This makes it a flexible choice for diverse computing environments. Resource efficiency helps maintain stable performance under load. Users get more done with fewer resources.
Comparing Oleanderstemminglibrary To Other Libraries
Comparing Oleanderstemminglibrary to other text processing libraries helps identify its unique features and limitations. This comparison guides developers in choosing the right tool for their projects. Each library offers different strengths, depending on the task and language requirements.
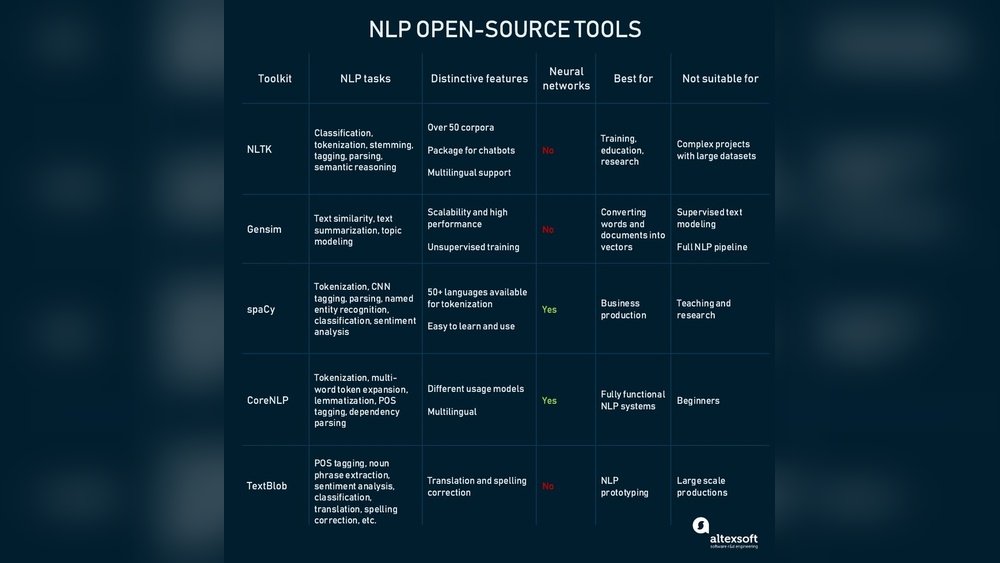
Popular Open Source Text Processing Tools
Several open source libraries dominate the text processing field. Libraries like NLTK, spaCy, and Stanford CoreNLP are widely used. NLTK is beginner-friendly and has many educational resources. SpaCy offers fast processing and easy integration. Stanford CoreNLP excels in deep linguistic analysis. Oleanderstemminglibrary focuses on efficient stemming and tokenization.
Strengths And Weaknesses
Oleanderstemminglibrary provides fast and accurate stemming for many languages. It uses advanced algorithms to reduce words to their root form. Its lightweight design fits well in resource-limited environments. However, it may lack some advanced NLP features like named entity recognition. Other libraries offer broader toolsets but can be slower or require more resources. Oleanderstemminglibrary’s simplicity makes it easier for specific tasks but less flexible for complex pipelines.
Best Use Cases
Oleanderstemminglibrary suits projects needing efficient word normalization. It works well in search engines, text classification, and information retrieval. Developers benefit from its speed in processing large datasets. Other libraries excel in tasks like sentiment analysis, parsing, or entity recognition. Choosing Oleanderstemminglibrary makes sense for projects focusing on stemming and lightweight text processing.
Implementing Oleanderstemminglibrary In Projects
Implementing Oleanderstemminglibrary in your projects can greatly simplify text processing tasks. This open source tool offers powerful stemming features that help reduce words to their root forms. Using it can improve search accuracy, text analysis, and data processing speed.
The library is designed to be easy to integrate into various software projects. It supports multiple programming languages and provides flexible options to fit different needs. Below are clear steps to install, use, and customize Oleanderstemminglibrary effectively.
Installation And Setup
Start by downloading the latest version of Oleanderstemminglibrary from the official repository. It is available as a package for popular platforms like Python and JavaScript. Use your package manager to install it quickly.
For example, in Python, run pip install oleanderstemminglibrary in your terminal. In JavaScript, use npm install oleanderstemminglibrary. After installation, import the library into your project files to access its functions.
Basic Usage Examples
Once installed, you can stem words easily. Import the stemmer class and call its stem method. Here is a simple example in Python:
from oleanderstemminglibrary import Stemmer stemmer = Stemmer() print(stemmer.stem('running')) Output: run This example shows how the library reduces “running” to “run”. You can stem single words or entire lists quickly. It works well with English and other supported languages.
Advanced Customization
Oleanderstemminglibrary allows you to adjust its behavior. You can customize stemming rules to better fit your project’s vocabulary. This is useful for domain-specific terms or slang.
Modify the configuration files or extend the stemmer class to add new rules. You can also disable certain rules if they do not apply. This flexibility helps improve accuracy and relevance in complex projects.
Community And Support
The Oleanderstemminglibrary thrives on a strong community and reliable support. This open source project brings together developers and users worldwide. They share ideas, report issues, and contribute code. The community fosters growth and ensures the library stays up-to-date and useful. Support is available through various channels, making it easy to get help and learn.
Open Source Contributions
Developers actively contribute to Oleanderstemminglibrary’s codebase. They add new features, fix bugs, and improve performance. Contributions come from beginners and experts alike. This collaboration keeps the project dynamic and responsive to user needs. Every pull request is reviewed carefully to maintain quality. Open contributions ensure the library evolves with current text processing trends.
Documentation And Tutorials
Clear documentation guides users through the library’s features. Step-by-step tutorials help beginners start quickly. Examples show how to implement common text processing tasks. The documentation is updated regularly to reflect new changes. It explains functions in simple terms for easy understanding. This resource helps users learn independently and solve problems efficiently.
User Community And Forums
Active forums and discussion boards support Oleanderstemminglibrary users. People share tips, ask questions, and offer solutions. Experienced members often help newcomers. The community encourages friendly and respectful interactions. These forums are a valuable place to exchange ideas and discover best practices. Users feel connected and supported throughout their journey with the library.

Credit: github.com
Future Developments And Roadmap
The Oleanderstemminglibrary project continues to evolve with a clear plan for future growth. Its roadmap focuses on enhancing functionality and adapting to new technology trends. Developers aim to keep the library useful and accessible for all users. The upcoming developments promise improved performance and broader applications.
Upcoming Features
New features will boost the library’s text processing power. Expect better support for multiple languages and dialects. The team plans to add customizable stemming rules. These will help users tailor the tool to specific tasks. Improved error handling and faster processing speeds are also on the list. These upgrades will make the library more reliable and efficient.
Integration With Emerging Technologies
Oleanderstemminglibrary will connect with new tech trends. Integration with machine learning frameworks is a priority. This will enhance automated text analysis and classification. The project also aims to support voice recognition systems. Such links will widen the library’s reach in AI applications. The library will work better with cloud platforms, too. This ensures easy scaling and collaboration across teams.
Long-term Project Vision
The long-term goal is to create a robust, flexible tool for text processing. The team envisions a community-driven development model. This model encourages users to contribute and share improvements. Sustainability and open access remain core principles. The project wants to stay relevant as language and technology evolve. It aims to empower developers worldwide with a reliable resource.
Frequently Asked Questions
What Is Oleanderstemminglibrary Used For?
Oleanderstemminglibrary is an open source tool for processing text data. It helps reduce words to their root forms. This makes text analysis simpler and faster.
How Does Oleanderstemminglibrary Improve Text Processing?
The library efficiently removes word endings to find stems. This reduces the number of word forms to handle. It helps improve search and data analysis accuracy.
Is Oleanderstemminglibrary Easy To Integrate With Projects?
Yes, Oleanderstemminglibrary is designed for easy integration. It supports common programming languages and formats. Developers can quickly add it to their text processing workflows.
What Languages Does Oleanderstemminglibrary Support?
Oleanderstemminglibrary mainly supports English text stemming. Some versions may include other languages. Check the project documentation for full language support details.
Where Can I Find Oleanderstemminglibrary’s Source Code?
The source code is available on popular open source platforms like GitHub. You can download, modify, and contribute to it freely. This encourages community collaboration and improvement.
Conclusion
Oleanderstemminglibrary offers a simple, open source tool for text processing. It helps break down words to their base forms quickly. Developers can use it to improve language data handling. The library supports many projects needing easy text analysis. Its open source nature allows for community improvements and sharing.
You can explore Oleanderstemminglibrary to see how it fits your needs. Text processing becomes clearer and faster with this helpful library.