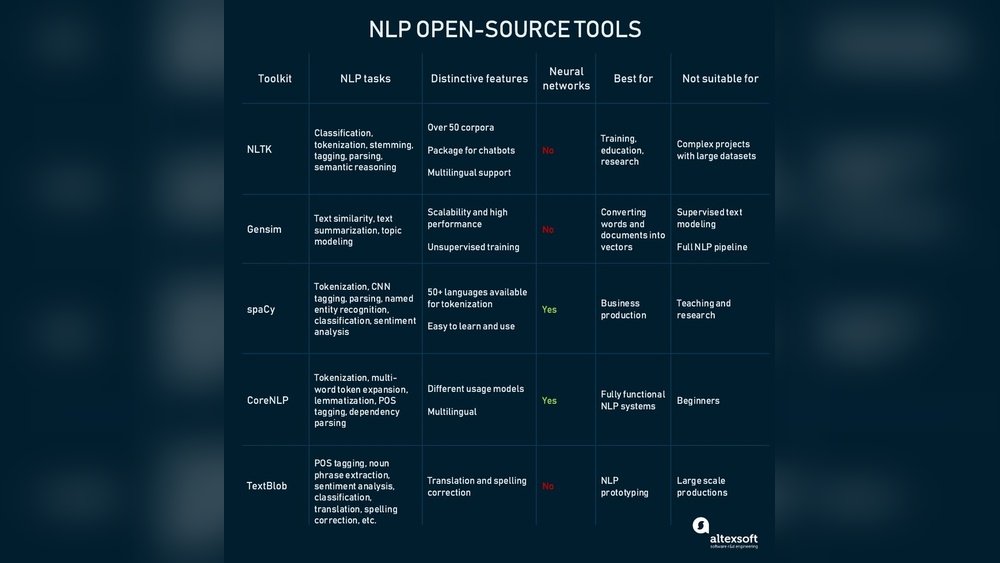
If you work with text data, you know how tricky it can be to make sense of language in a way computers understand. That’s where the Open Source Text Processing Project Linguastem comes in.
Imagine having a powerful tool that helps you analyze, break down, and process text quickly and accurately—without costly licenses or complicated setups. Linguastem offers exactly that, giving you the freedom to customize and enhance your text projects with ease. Whether you’re developing chatbots, analyzing customer feedback, or building language models, this project could change the way you handle language data.
Keep reading to discover how Linguastem can transform your text processing tasks and boost your productivity.

Credit: packagehub.suse.com
Linguastem Overview
Linguastem is an open source project focused on text processing. It helps analyze and transform language data efficiently. The project supports various natural language processing tasks. It is designed to be accessible for developers and researchers alike.
Its modular design allows easy integration with other tools. Users can customize features based on their project needs. Linguastem aims to simplify complex language processing operations.
Core Features
Linguastem offers powerful text segmentation and tokenization. It supports part-of-speech tagging to identify word types. Named entity recognition is included to detect names and locations. The project provides dependency parsing to understand sentence structure. It also allows lemmatization to find the base form of words.
Users can easily extend the toolkit with custom modules. The framework supports batch processing for large datasets. It includes tools for cleaning and normalizing text data. These features streamline many common text analysis tasks.
Supported Languages
Linguastem supports multiple languages to serve a broad audience. English is fully supported with rich linguistic models. Spanish, French, and German also have strong support. The project is expanding to cover Asian and Slavic languages. This makes it useful for global applications and research.
Each language model includes tailored components for better accuracy. Developers can contribute new language support easily. Continuous updates improve the quality and coverage of languages.
Technology Stack
The project uses Python as its main programming language. Python ensures readability and ease of use. It leverages advanced machine learning libraries for model training. Core algorithms rely on libraries like TensorFlow and PyTorch. For fast processing, some modules use C++ extensions.
Linguastem employs JSON and XML for data interchange. It integrates well with other open source NLP tools. The codebase follows modern software development practices. This results in a stable and maintainable platform.

Credit: packagehub.suse.com
Text Processing Capabilities
Linguastem offers robust text processing capabilities essential for natural language understanding. These features help break down and analyze text efficiently. The project supports various tasks that prepare text for deeper analysis and applications.
Each capability is designed to handle language data with accuracy and speed. Linguastem’s tools serve as building blocks for many language processing workflows. Users can rely on these functions to improve text analysis results.
Tokenization And Lemmatization
Tokenization splits text into words or phrases. This step makes it easier to analyze the text piece by piece. Linguastem’s tokenizer handles punctuation and spacing accurately. It supports multiple languages and writing styles.
Lemmatization reduces words to their base forms. It groups related words for better understanding. For example, “running” becomes “run.” This process helps in simplifying text and improving search and analysis.
Named Entity Recognition
Linguastem identifies named entities like people, places, and dates. This helps extract key information from text. The system can spot names, organizations, and locations automatically. It improves data extraction and supports many applications such as summarization and search.
Part-of-speech Tagging
This feature assigns grammatical tags to each word. Tags indicate if a word is a noun, verb, adjective, and more. Accurate tagging helps understand sentence structure. Linguastem’s tagging is fast and precise, aiding further language analysis tasks.
Workflow Integration
Integrating Linguastem into your existing workflow is simple and efficient. The project offers flexible options that fit many development environments and tools. It supports smooth data processing and automation, saving time and reducing errors.
With easy integration, developers can focus on building applications rather than dealing with complex setups. Linguastem adapts well to different systems and pipelines, making it a practical choice for text processing tasks.
Api And Sdk Options
Linguastem provides a robust API for direct access to its features. Developers can use the API to send text data and receive processed results quickly. The SDK supports multiple programming languages, making it easy to add Linguastem to your projects.
The API uses simple commands and clear responses, which helps reduce coding time. SDK libraries include detailed documentation and examples, helping users implement the tool without hassle.
Compatibility With Popular Tools
Linguastem works well with many popular text and data processing tools. It supports integration with platforms like Apache Spark, TensorFlow, and various database systems. This compatibility allows users to combine Linguastem’s power with other software they already use.
Its open-source nature means developers can customize it to fit their specific toolchains. This flexibility enhances collaboration and streamlines workflows across different teams and projects.
Automation And Pipeline Support
Linguastem supports automation to handle large text datasets effortlessly. Users can create processing pipelines that run without manual intervention. This capability speeds up repetitive tasks and improves consistency in results.
Pipeline support includes batch processing and real-time data handling. This makes Linguastem suitable for both research and production environments that require reliable text analysis.
Open Source Community
The Open Source Community is the heart of the Linguastem project. It brings together developers, linguists, and users who share a passion for text processing. This community thrives on collaboration and shared knowledge. Everyone can join and contribute to make Linguastem better for all.
Members learn from each other and solve problems as a team. The community also helps new users get started quickly. Open discussions keep the project active and fresh. This spirit of openness drives innovation and quality in Linguastem.
Contribution Guidelines
Linguastem has clear rules for contributions. These guidelines help maintain code quality and consistency. They explain how to report issues and submit patches. Contributors must follow coding standards and write clear documentation. This makes it easier for others to review and use the changes. New contributors find these guidelines useful to start their work smoothly.
Community Support Channels
The community uses various channels to offer support. Forums and chat rooms allow users to ask questions. Developers share tips and troubleshoot problems together. Mailing lists keep everyone updated on project news. These channels create a friendly space for learning and growth. Quick responses help keep the project moving forward.
Collaborative Development
Collaboration is key in Linguastem’s development process. Contributors work on features and fixes in shared repositories. Code reviews ensure high quality before merging changes. This teamwork spreads knowledge and improves skills. Regular meetings and discussions guide the project’s direction. Together, the community builds a robust and evolving text processing tool.
Performance And Scalability
The performance and scalability of Linguastem make it a strong choice for text processing tasks. It handles complex language data quickly and efficiently. This ensures smooth operation even under heavy workloads. Users benefit from fast processing times and robust system behavior. The design supports growth, allowing projects to expand without losing speed or accuracy.
Benchmark Comparisons
Linguastem performs well in benchmark tests against similar tools. It processes text faster while maintaining high accuracy. Tests show consistent results across different languages and data types. These benchmarks highlight its ability to handle various text processing challenges. Developers trust Linguastem for reliable and speedy outcomes.
Handling Large Datasets
Linguastem manages large datasets with ease. It uses efficient memory management to avoid slowdowns. The system processes millions of words without crashing or lagging. This makes it suitable for big data projects and real-time applications. Users can scale their text analysis without fear of performance loss.
Optimization Techniques
Linguastem uses smart optimization methods to boost speed and reduce resource use. It applies parallel processing to handle multiple tasks at once. Code is streamlined for quicker execution and less overhead. The project also adapts to hardware capabilities to maximize performance. These techniques ensure Linguastem runs smoothly on many systems.
Use Cases And Applications
The Open Source Text Processing Project Linguastem offers powerful tools for handling language data. Its flexible design supports many types of text processing tasks. The project helps users extract meaningful information from large text collections. It serves various industries and technologies by making text analysis simpler and faster.
Linguastem finds uses in business, media, and interactive systems. It supports tasks from data mining to user communication. Below are some key applications where Linguastem delivers strong value.
Business Intelligence
Companies use Linguastem to analyze customer feedback and market trends. It processes reviews, surveys, and social media posts to detect sentiment and opinions. This helps businesses understand their audience better and make informed decisions. It also supports competitive analysis by extracting key insights from public data.
Content Analysis
Media and publishing industries rely on Linguastem to organize large volumes of text. It categorizes articles, identifies topics, and summarizes content quickly. This speeds up editorial work and improves content management. Linguastem also detects plagiarism and checks for language quality in texts.
Chatbots And Virtual Assistants
Linguastem enhances chatbots by enabling them to understand and respond to natural language. It helps in recognizing user intent and extracting relevant details from messages. This makes conversations smoother and more accurate. Virtual assistants benefit from its ability to parse complex queries and provide helpful replies.
Getting Started
Starting with Linguastem is simple and straightforward. This open source text processing project offers powerful tools to analyze and understand language data. Beginners can quickly set up the environment and explore its features.
The following sections guide you through installation, sample projects, and best practices. Each step helps you build confidence and skills with Linguastem.
Installation Steps
Download the latest version of Linguastem from the official repository. Make sure you have Python 3.7 or higher installed on your system. Use the command pip install linguastem in your terminal or command prompt. This installs all necessary packages and dependencies automatically. Verify the installation by running linguastem --version. If the version appears, you are ready to proceed.
Sample Projects
Explore sample projects included in the Linguastem package. These projects demonstrate common text processing tasks like tokenization, stemming, and language detection. Open the examples folder in your installation directory. Run the Python scripts to see how the library works with real data. Modify the code to experiment with different inputs. This hands-on practice helps you understand the tool’s capabilities quickly.
Best Practices
Organize your code into clear, reusable functions. Comment your scripts to explain each step and decision. Use virtual environments to keep project dependencies separate and manageable. Test your code with different types of text data to ensure robustness. Keep your Linguastem library updated to benefit from new features and fixes. Follow these habits to maintain clean and effective text processing workflows.

Credit: distrowatch.com
Future Developments
The future of the Linguastem project promises exciting growth and innovation. The team behind this open source text processing tool plans to add new features and improve existing ones. These updates aim to make Linguastem more efficient and easier to use for developers and researchers alike.
With a clear roadmap and active community engagement, Linguastem is set to stay at the forefront of natural language processing. The project’s future will focus on expanding capabilities while maintaining open collaboration.
Upcoming Features
Linguastem will introduce advanced syntax parsing to improve text analysis. Enhanced support for multiple languages will allow more global users to benefit from the project. New tools for text summarization and sentiment analysis will help users extract key information quickly. The project also plans to optimize performance for faster processing on large datasets.
Roadmap Highlights
The roadmap outlines a phased approach for delivering new capabilities. Early stages focus on improving core algorithms and expanding language models. Mid-term goals include building user-friendly interfaces and better integration with other NLP tools. Later phases will prioritize scalability and cloud deployment options. Regular updates will keep the project aligned with user needs and industry trends.
Community Initiatives
The Linguastem community plays a vital role in shaping its future. Contributors collaborate on code, documentation, and testing to improve quality. The team encourages new members to join through forums and workshops. Open discussions help prioritize features and fix bugs faster. Community-driven projects will create custom modules and plugins to extend Linguastem’s reach.
Frequently Asked Questions
What Is Linguastem In Text Processing?
Linguastem is an open source project for text processing tasks. It helps analyze and understand natural language data efficiently.
How Does Linguastem Improve Natural Language Processing?
Linguastem offers tools to break down text into meaningful parts. This improves language analysis and machine understanding.
Which Languages Does Linguastem Support?
Linguastem mainly supports widely used languages like English, Spanish, and French. It continues expanding to include more languages.
Can Developers Customize Linguastem For Projects?
Yes, Linguastem is open source and allows developers to modify its code. This flexibility helps tailor it to specific needs.
Where Can I Access The Linguastem Project?
Linguastem is available on popular code platforms like GitHub. You can download, use, and contribute to its development there.
Conclusion
Linguastem offers a simple and effective way to process text data. Its open source nature invites collaboration and improvement. Users can adapt it for many languages and projects. The tool helps make sense of large text collections quickly. Developers and learners find Linguastem easy to use and understand.
Try it to explore text processing without complex setups. This project supports the growing need for accessible language tools. It stands as a practical choice for text analysis tasks.