If you’re diving into the world of machine translation or natural language processing, mastering word alignment is a key step. And that’s where Giza++ comes in.
This powerful tool helps you connect words from one language to their counterparts in another, unlocking the secrets of how languages relate. But getting started with Giza++ can feel overwhelming if you don’t know where to begin. Don’t worry—this guide is designed just for you.
By the end, you’ll understand how to set up Giza++ and use it to align words accurately, giving your language projects a solid foundation. Ready to make your translations smarter and smoother? Let’s get started!
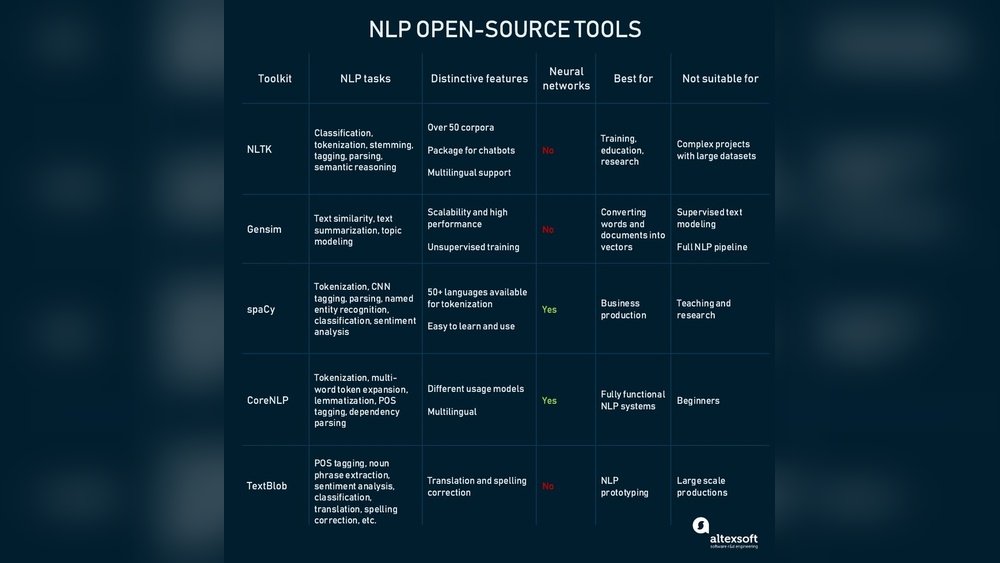
What Is Giza++
Giza++ is a tool used for aligning words between two languages in translation tasks. It helps find which words match across sentences in different languages. This alignment is important for building better translation systems.
What Is Giza++?
Giza++ is a popular tool used in natural language processing. It helps align words between two languages. This alignment is important for machine translation and language research.
The tool uses statistical models to find word correspondences. It learns patterns from large sets of bilingual text. This process is called training.
Giza++ builds on the original GIZA software. It offers improved speed and flexibility. Many researchers prefer Giza++ for word alignment tasks.
How Does Giza++ Work?
Giza++ uses several statistical models to analyze text. It starts with simple models and moves to more complex ones. These models estimate the probability of word matches.
The training process involves aligning sentences from two languages. Giza++ calculates which words likely correspond to each other. It refines these alignments through multiple iterations.
The output is a set of word alignment pairs. These pairs show connections between source and target language words.
Why Use Giza++ For Word Alignment?
Giza++ provides accurate and reliable word alignments. It supports many language pairs and large datasets. The tool is open-source and widely used in the research community.
It integrates well with other machine translation systems. This makes it a valuable resource for developers and linguists. Giza++ also produces detailed alignment data for analysis.
Where To Find Giza++?
Giza++ is available as a free download on GitHub. Users can compile it on different operating systems. Many tutorials and guides help with installation and use.
Using Giza++ requires basic knowledge of command-line tools. Once set up, it can process large corpora efficiently. This makes it ideal for research and practical applications.
Why Word Alignment Matters
Word alignment plays a key role in language processing. It connects words from one language to their counterparts in another. This connection helps machines understand how languages relate. Without word alignment, translation and language tasks become much harder.
Giza is a popular tool for word alignment. It uses statistical models to find word connections. These connections improve machine translation accuracy. They also help in creating bilingual dictionaries and language learning tools.
Improving Machine Translation Accuracy
Word alignment helps machines match words correctly between languages. This matching reduces errors in translated text. It ensures the meaning stays the same in both languages. Better alignment leads to clearer and more natural translations.
Building Bilingual Dictionaries
Word alignment identifies equivalent words across languages. These pairs form the basis of bilingual dictionaries. These dictionaries support language learners and translators. They also assist in many language technology applications.
Enhancing Language Learning Tools
Aligned words show learners how languages correspond. This helps in understanding grammar and vocabulary. Learning tools use alignment to create exercises and examples. It makes language learning more effective and engaging.
Supporting Cross-language Information Retrieval
Word alignment allows searching for information in one language. The system finds matching content in another language. This support broadens access to information worldwide. It helps users find relevant data across different languages.
Setting Up Giza++
Setting up Giza++ is the first step for effective word alignment in language processing. This tool helps find word correspondences between source and target texts. Getting it ready requires careful preparation and following clear steps.
Below are the key points to set up Giza++ on your system. These will guide you through requirements, installation, and common problems.
System Requirements
Giza++ runs best on Unix-like systems such as Linux or macOS. A Windows environment needs a compatibility layer like Cygwin.
The system should have at least 4 GB of RAM for smooth operation. A multi-core processor speeds up training.
Install essential tools: a C++ compiler (g++), GNU Make, and Perl. These support building and running Giza++.
Installation Steps
First, download the Giza++ source code from the official repository or trusted sites. Extract the files to a working directory.
Open a terminal and navigate to the extracted folder. Run make to compile the source code.
If the compilation finishes without errors, the Giza++ executables will be ready in the folder.
Test the installation by running ./GIZA++ -help. This shows the usage instructions.
Common Setup Issues
Compilation errors often occur due to missing dependencies or outdated compilers. Check if g++, make, and Perl are installed.
On Windows, ensure Cygwin is fully set up with development tools included. Missing packages cause build failures.
File permission problems may stop executables from running. Use chmod +x to fix permissions.
Errors in input file formats can cause runtime failures. Verify your training data matches Giza++ requirements.

Credit: www.egypttoursportal.com
Preparing Data For Alignment
Preparing data for alignment is the first step in using Giza effectively. Good data preparation ensures accurate word alignment results. It involves cleaning text, formatting it correctly, and handling language differences. This section guides you through these essential tasks.
Cleaning And Formatting Text
Remove extra spaces, tabs, and special characters from your text. Keep only letters and punctuation needed for alignment. Convert all text to lowercase to avoid mismatches. Make sure sentences are complete and correctly punctuated. Save each sentence on a new line for better processing.
Creating Required Input Files
Giza requires two parallel files: one for the source language and one for the target. Both files must have the same number of lines. Each line should contain a sentence that matches its translation in the other file. Use plain text format without any additional markup or tags. Check for empty lines or mismatched sentences before starting alignment.
Handling Different Language Pairs
Languages can have different structures and scripts. For example, English uses Latin script, while Arabic uses Arabic script. Make sure your text encoding supports these scripts, like UTF-8. Tokenize sentences properly for each language. Some languages need special tokenizers to split words correctly. Aligning distant languages may require more cleaning and tuning.
Running Giza++
Running Giza++ is a key step in word alignment for statistical machine translation. It aligns words between two languages by analyzing sentence pairs. This process requires understanding basic commands, preparing word classes, and managing system resources. Following clear steps helps avoid errors and speeds up alignment.
Basic Command Usage
Start Giza++ by running the command in your terminal or command prompt. Use the following format:
GIZA++ -S source.vcb -T target.vcb -C corpus.snt -o outputHere, -S specifies the source vocabulary file, -T the target vocabulary, and -C the corpus file. The -o option names the output files. Make sure your files are correctly formatted and in the same folder.
Using Mkcls For Word Classes
Before running Giza++, use mkcls to group words into classes. This helps improve alignment quality and speed. Run this command:
mkcls -c50 -n2 -pcorpus.snt -Vcorpus.vcb.classesThe -c50 sets the number of word classes to 50. Adjust this number for larger or smaller vocabularies. The -p option points to your corpus, and -V names the output class file. Use this class file with Giza++ for better results.
Managing Memory And Performance
Giza++ can use a lot of memory and CPU. Limit memory use by adjusting parameters in the command line. For example, add -m followed by the maximum memory in MB.
Run Giza++ on a machine with enough RAM for large corpora. Use fewer CPU cores if your system slows down. Monitor usage with system tools to avoid crashes. Splitting big data files into smaller parts also helps manage performance.

Credit: www.nationalgeographic.com
Analyzing Alignment Results
After running Giza for word alignment, the next step is to analyze the results. This step helps you understand how well the words from two languages match. Careful analysis can reveal the quality of your alignment and guide improvements. The alignment output files contain valuable information but need careful reading. Visual tools can also help you see the connections clearly. Knowing common errors helps fix problems quickly and improves future runs.
Interpreting Output Files
Giza creates several output files with alignment data. The most important file shows word pairs linked by the model. Each line represents one sentence pair with word indexes. Numbers indicate which source words align with target words. Empty alignments mean no match was found for some words. Look for strong links between related words. Weak or missing links could mean poor data or model issues. Check word counts in source and target files to ensure they match. Consistency here is key for good alignment.
Visualizing Word Alignments
Visual tools turn alignment data into easy-to-understand graphics. They show lines connecting words in source and target sentences. This helps spot correct and incorrect matches quickly. Some tools allow zooming and filtering to focus on problem areas. Color coding can highlight strong versus weak links. Visualization helps non-experts grasp alignment quality without digging into text files. It also aids in presentations or reports on your work. Using these tools speeds up error detection and correction.
Common Errors And Fixes
Many errors arise from data issues, such as mismatched sentence pairs. Check that source and target sentences line up properly. Another common error is poor tokenization, which breaks words wrongly. Use the same tokenizer for both languages. Low frequency words may have weak or no alignment. Increasing data size can help here. Model parameters might also need tuning for better results. If alignments look random, review your training steps and input files. Fixing these errors improves alignment accuracy significantly.
Advanced Tips
Getting the most out of Giza for word alignment requires a few advanced strategies. These tips help you improve results and solve common issues. Follow these steps to enhance your workflow and get better accuracy with your alignments.
Improving Alignment Accuracy
Start by cleaning your data carefully. Remove noise and inconsistencies in your text. Use tokenization to split sentences into words properly. Check for correct sentence pairs in your bilingual data. Adjust Giza’s training parameters for better model fitting. Experiment with different iterations and smoothing options. Use larger, high-quality corpora to train the models. This helps Giza learn better word relationships. Evaluate your alignments regularly and refine your process.
Using Giza++ With Other Tools
Combine Giza++ with tools like Moses for phrase-based translation. Use scripts to convert Giza output into formats needed by other software. Integrate Giza++ with alignment visualization tools to inspect results. Pair it with tokenizer and truecaser tools for cleaner input. Use MGIZA++ for multi-threaded processing and faster training. Coordinate Giza++ output with language models to improve translation quality. These combinations create a smoother workflow for your projects.
Troubleshooting Common Problems
Check for errors in your input files first. Make sure sentence pairs match exactly in number. Look for encoding issues that can cause misalignment. Verify that Giza++ is installed correctly and dependencies are met. Inspect log files for warnings or errors during training. If alignment quality is low, try adjusting training settings. Restart training with smaller datasets to isolate problems. Use community forums and documentation for further help.
Resources And Further Learning
Exploring resources and further learning materials can boost your understanding of Giza for word alignment. These resources help beginners and advanced users improve their skills. They cover practical steps, tips, and troubleshooting advice. Use these materials to deepen your knowledge and solve problems quickly.
Useful Tutorials And Guides
Start with beginner-friendly tutorials that explain Giza’s basics clearly. Step-by-step guides show how to install and run Giza effectively. Video tutorials provide visual learning for better comprehension. Look for examples using real data to practice alongside. These tutorials help build confidence in using Giza.
Community And Support Forums
Join forums where users share questions and solutions about Giza. These communities offer peer support and expert advice. Active forums often include discussions on updates and best practices. Participation helps you stay updated and solve issues faster. Reading others’ experiences can also provide new insights.
Related Software And Tools
Explore software that complements Giza for enhanced word alignment. Tools like MGIZA++ offer faster processing and extra features. Visualization tools help interpret alignment results visually. Integration with machine translation toolkits can expand functionality. Using related tools can improve workflow and output quality.

Credit: brookebeyond.com
Frequently Asked Questions
How To Get Perfect Alignment In Word?
Select the text, go to the Home tab, and choose left, center, right, or justified alignment. Use the ruler for precise adjustments.
What Is Giza++?
GIZA++ is a tool for automatic word alignment in statistical machine translation. It identifies word correspondences between languages.
What Are The 4 Types Of Alignment In Word?
The four types of alignment in Word are left, center, right, and justified. Each aligns text differently on the page.
How To Use The Word “alignment”?
Use “alignment” to describe arranging elements in a straight line or correct position. For example, “text alignment” means positioning text left, right, or center. It also refers to agreement or coordination between ideas, goals, or parts in a system or group.
What Is Giza In Word Alignment?
Giza is a tool for aligning words in bilingual text pairs. It helps find matching words between two languages. This is useful for machine translation and language learning.
Conclusion
Giza offers a practical way to start word alignment quickly. It helps link words between two languages clearly. By following simple steps, you can set up and run Giza with ease. Practice will improve your understanding and results. Word alignment supports better translation and language study.
Keep exploring Giza to see how it fits your needs. This tool is a solid choice for language learners and developers alike.