
About spaCy
Open Source Text Processing Project: spaCy
Install spaCy and related data model
Install spaCy by pip:
sudo pip install -U spacy
Collecting spacy
Downloading spacy-1.8.2.tar.gz (3.3MB)
Downloading numpy-1.13.0-cp27-cp27mu-manylinux1_x86_64.whl (16.6MB)
Collecting murmurhash<0.27,>=0.26 (from spacy)
Downloading murmurhash-0.26.4-cp27-cp27mu-manylinux1_x86_64.whl
Collecting cymem<1.32,>=1.30 (from spacy)
Downloading cymem-1.31.2-cp27-cp27mu-manylinux1_x86_64.whl (66kB)
Collecting ftfy<5.0.0,>=4.4.2 (from spacy)
Downloading ftfy-4.4.3.tar.gz (50kB)
Collecting cytoolz<0.9,>=0.8 (from thinc<6.6.0,>=6.5.0->spacy)
Downloading cytoolz-0.8.2.tar.gz (386kB)
Downloading termcolor-1.1.0.tar.gz
Collecting idna<2.6,>=2.5 (from requests<3.0.0,>=2.13.0->spacy)
Downloading idna-2.5-py2.py3-none-any.whl (55kB)
Collecting urllib3<1.22,>=1.21.1 (from requests<3.0.0,>=2.13.0->spacy)
Downloading urllib3-1.21.1-py2.py3-none-any.whl (131kB)
Collecting chardet<3.1.0,>=3.0.2 (from requests<3.0.0,>=2.13.0->spacy)
Downloading chardet-3.0.4-py2.py3-none-any.whl (133kB)
Collecting certifi>=2017.4.17 (from requests<3.0.0,>=2.13.0->spacy)
Downloading certifi-2017.4.17-py2.py3-none-any.whl (375kB)
Collecting html5lib (from ftfy<5.0.0,>=4.4.2->spacy)
Downloading html5lib-0.999999999-py2.py3-none-any.whl (112kB)
Collecting wcwidth (from ftfy<5.0.0,>=4.4.2->spacy)
Downloading wcwidth-0.1.7-py2.py3-none-any.whl
Collecting toolz>=0.8.0 (from cytoolz<0.9,>=0.8->thinc<6.6.0,>=6.5.0->spacy)
Downloading toolz-0.8.2.tar.gz (45kB)
Collecting setuptools>=18.5 (from html5lib->ftfy<5.0.0,>=4.4.2->spacy)
Installing collected packages: numpy, murmurhash, cymem, preshed, wrapt, tqdm, toolz, cytoolz, plac, dill, termcolor, pathlib, thinc, ujson, idna, urllib3, chardet, certifi, requests, regex, setuptools, webencodings, html5lib, wcwidth, ftfy, spacy
Found existing installation: numpy 1.12.0
Uninstalling numpy-1.12.0:
Successfully uninstalled numpy-1.12.0
Running setup.py install for preshed ... done
Running setup.py install for wrapt ... done
Running setup.py install for toolz ... done
Running setup.py install for cytoolz ... done
Running setup.py install for dill ... done
Running setup.py install for termcolor ... done
Running setup.py install for pathlib ... done
Running setup.py install for thinc ... done
Running setup.py install for ujson ... done
Found existing installation: requests 2.13.0
Uninstalling requests-2.13.0:
Successfully uninstalled requests-2.13.0
Running setup.py install for regex ... done
Found existing installation: setuptools 20.7.0
Uninstalling setuptools-20.7.0:
Successfully uninstalled setuptools-20.7.0
Running setup.py install for ftfy ... done
Running setup.py install for spacy ... -
done
Successfully installed certifi-2017.4.17 chardet-3.0.4 cymem-1.31.2 cytoolz-0.8.2 dill-0.2.6 ftfy-4.4.3 html5lib-0.999999999 idna-2.5 murmurhash-0.26.4 numpy-1.13.0 pathlib-1.0.1 plac-0.9.6 preshed-1.0.0 regex-2017.4.5 requests-2.18.1 setuptools-36.0.1 spacy-1.8.2 termcolor-1.1.0 thinc-6.5.2 toolz-0.8.2 tqdm-4.14.0 ujson-1.35 urllib3-1.21.1 wcwidth-0.1.7 webencodings-0.5.1 wrapt-1.10.10
Download related default English model data:
sudo python -m spacy download en
Test spacy by pytest:
python -m pytest /usr/local/lib/python2.7/dist-packages/spacy --vectors --models --slow
============================= test session starts ============================== platform linux2 -- Python 2.7.12, pytest-3.1.2, py-1.4.34, pluggy-0.4.0 rootdir: /usr/local/lib/python2.7/dist-packages/spacy, inifile: collected 2932 items ../../usr/local/lib/python2.7/dist-packages/spacy/tests/test_attrs.py ... ../../usr/local/lib/python2.7/dist-packages/spacy/tests/test_cli.py ...... ../../usr/local/lib/python2.7/dist-packages/spacy/tests/test_misc.py .. ../../usr/local/lib/python2.7/dist-packages/spacy/tests/test_orth.py ....................................................... ../../usr/local/lib/python2.7/dist-packages/spacy/tests/test_pickles.py .X ../../usr/local/lib/python2.7/dist-packages/spacy/tests/doc/test_add_entities.py . ../../usr/local/lib/python2.7/dist-packages/spacy/tests/doc/test_array.py ... ../../usr/local/lib/python2.7/dist-packages/spacy/tests/doc/test_doc_api.py ............ ../../usr/local/lib/python2.7/dist-packages/spacy/tests/doc/test_noun_chunks.py . ../../usr/local/lib/python2.7/dist-packages/spacy/tests/doc/test_token_api.py ........ ../../usr/local/lib/python2.7/dist-packages/spacy/tests/matcher/test_entity_id.py ... ../../usr/local/lib/python2.7/dist-packages/spacy/tests/matcher/test_matcher.py ........... ../../usr/local/lib/python2.7/dist-packages/spacy/tests/parser/test_ner.py ... ../../usr/local/lib/python2.7/dist-packages/spacy/tests/parser/test_nonproj.py ..... ../../usr/local/lib/python2.7/dist-packages/spacy/tests/parser/test_noun_chunks.py ..... ../../usr/local/lib/python2.7/dist-packages/spacy/tests/parser/test_parse.py ...... ../../usr/local/lib/python2.7/dist-packages/spacy/tests/parser/test_parse_navigate.py ... ../../usr/local/lib/python2.7/dist-packages/spacy/tests/parser/test_sbd.py ...... ../../usr/local/lib/python2.7/dist-packages/spacy/tests/parser/test_sbd_prag.py ..x....x.....xx..x......x.....xxx.xxxxx..x..x..x.xxx ../../usr/local/lib/python2.7/dist-packages/spacy/tests/parser/test_space_attachment.py ...... ../../usr/local/lib/python2.7/dist-packages/spacy/tests/serialize/test_codecs.py ... ../../usr/local/lib/python2.7/dist-packages/spacy/tests/serialize/test_huffman.py ..... ../../usr/local/lib/python2.7/dist-packages/spacy/tests/serialize/test_io.py ... ../../usr/local/lib/python2.7/dist-packages/spacy/tests/serialize/test_packer.py ..... ../../usr/local/lib/python2.7/dist-packages/spacy/tests/serialize/test_serialization.py .......... ../../usr/local/lib/python2.7/dist-packages/spacy/tests/spans/test_merge.py ...... ../../usr/local/lib/python2.7/dist-packages/spacy/tests/spans/test_span.py ........ ../../usr/local/lib/python2.7/dist-packages/spacy/tests/stringstore/test_freeze_string_store.py . ../../usr/local/lib/python2.7/dist-packages/spacy/tests/stringstore/test_stringstore.py .......... ../../usr/local/lib/python2.7/dist-packages/spacy/tests/tagger/test_lemmatizer.py .....x... ../../usr/local/lib/python2.7/dist-packages/spacy/tests/tagger/test_morph_exceptions.py . ../../usr/local/lib/python2.7/dist-packages/spacy/tests/tagger/test_spaces.py .. ../../usr/local/lib/python2.7/dist-packages/spacy/tests/tagger/test_tag_names.py . ../../usr/local/lib/python2.7/dist-packages/spacy/tests/tokenizer/test_exceptions.py ............................................ ../../usr/local/lib/python2.7/dist-packages/spacy/tests/tokenizer/test_tokenizer.py ............................................................................................................................................................................................ ../../usr/local/lib/python2.7/dist-packages/spacy/tests/tokenizer/test_urls.py ...................................xx...................................xxx..................................................................................................................................................................................................................................................... ../../usr/local/lib/python2.7/dist-packages/spacy/tests/tokenizer/test_whitespace.py ............................................................................. ../../usr/local/lib/python2.7/dist-packages/spacy/tests/vectors/test_similarity.py ..... ../../usr/local/lib/python2.7/dist-packages/spacy/tests/vectors/test_vectors.py ............... ../../usr/local/lib/python2.7/dist-packages/spacy/tests/vocab/test_add_vectors.py . ../../usr/local/lib/python2.7/dist-packages/spacy/tests/vocab/test_lexeme.py ...... ../../usr/local/lib/python2.7/dist-packages/spacy/tests/vocab/test_vocab_api.py .................... ============ 2905 passed, 26 xfailed, 1 xpassed in 1549.45 seconds =============
How to use spaCy
textminer@ubuntu:~$ ipython Python 2.7.12 (default, Nov 19 2016, 06:48:10) Type "copyright", "credits" or "license" for more information. IPython 2.4.1 -- An enhanced Interactive Python. ? -> Introduction and overview of IPython's features. %quickref -> Quick reference. help -> Python's own help system. object? -> Details about 'object', use 'object??' for extra details. In [1]: import spacy In [2]: spacy_en = spacy.load('en') In [3]: test_texts = u""" Natural language processing (NLP) is a field of computer science, artificial intelligence and computational linguistics concerned with the interactions between computers and human (natural) languages, and, in particular, concerned with programming computers to fruitfully process large natural language corpora. Challenges in natural language processing frequently involve natural language understanding, natural language generation (frequently from formal, machine-readable logical forms), connecting language and machine perception, dialog systems, or some combination thereof.""" In [4]: test_doc = spacy_en(test_texts) In [6]: print(test_doc) Natural language processing (NLP) is a field of computer science, artificial intelligence and computational linguistics concerned with the interactions between computers and human (natural) languages, and, in particular, concerned with programming computers to fruitfully process large natural language corpora. Challenges in natural language processing frequently involve natural language understanding, natural language generation (frequently from formal, machine-readable logical forms), connecting language and machine perception, dialog systems, or some combination thereof. In [7]: dir(test_doc) Out[7]: ['__bytes__', '__class__', '__delattr__', '__doc__', '__format__', '__getattribute__', '__getitem__', '__hash__', '__init__', '__iter__', '__len__', '__new__', '__pyx_vtable__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__unicode__', '_py_tokens', '_realloc', '_vector', '_vector_norm', 'count_by', 'doc', 'ents', 'from_array', 'from_bytes', 'has_vector', 'is_parsed', 'is_tagged', 'mem', 'merge', 'noun_chunks', 'noun_chunks_iterator', 'read_bytes', 'sentiment', 'sents', 'similarity', 'string', 'tensor', 'text', 'text_with_ws', 'to_array', 'to_bytes', 'user_data', 'user_hooks', 'user_span_hooks', 'user_token_hooks', 'vector', 'vector_norm', 'vocab'] # Word Tokenization In [8]: for token in test_doc[:20]: ...: print(token) ...: Natural language processing ( NLP ) is a field of computer science , artificial intelligence and computational linguistics concerned # Sentence Tokenization or Sentence Segmentation In [9]: for sent in test_doc.sents: ...: print(sent) ...: Natural language processing (NLP) is a field of computer science, artificial intelligence and computational linguistics concerned with the interactions between computers and human (natural) languages, and, in particular, concerned with programming computers to fruitfully process large natural language corpora. Challenges in natural language processing frequently involve natural language understanding, natural language generation (frequently from formal, machine-readable logical forms), connecting language and machine perception, dialog systems, or some combination thereof. In [10]: for sent_num, sent in enumerate(test_doc.sents, 1): ....: print(sent_num, sent) ....: (1, Natural language processing (NLP) is a field of computer science, artificial intelligence and computational linguistics concerned with the interactions between computers and human (natural) languages, and, in particular, concerned with programming computers to fruitfully process large natural language corpora.) (2, Challenges in natural language processing frequently involve natural language understanding, natural language generation (frequently from formal, machine-readable logical forms), connecting language and machine perception, dialog systems, or some combination thereof.) # Id it In [11]: NLP_id = spacy_en.vocab.strings['NLP'] In [12]: print(NLP_id) 289622 In [13]: NLP_str = spa spacy spacy_en In [13]: NLP_str = spacy_en.vocab.strings[NLP_id] In [14]: print(NLP_str) NLP # Pos Tagging: In [15]: for token in test_doc[:20]: ....: print(token, token.pos, token.pos_) ....: ( , 101, u'SPACE') (Natural, 82, u'ADJ') (language, 90, u'NOUN') (processing, 90, u'NOUN') ((, 95, u'PUNCT') (NLP, 94, u'PROPN') (), 95, u'PUNCT') (is, 98, u'VERB') (a, 88, u'DET') (field, 90, u'NOUN') (of, 83, u'ADP') (computer, 90, u'NOUN') (science, 90, u'NOUN') (,, 95, u'PUNCT') (artificial, 82, u'ADJ') (intelligence, 90, u'NOUN') (and, 87, u'CCONJ') (computational, 82, u'ADJ') (linguistics, 90, u'NOUN') (concerned, 98, u'VERB') # Named-entity recognition (NER) In [16]: for ent in test_doc.ents: ....: print(ent, ent.label, ent.label_) ....: ( Natural language, 382, u'LOC') (NLP, 380, u'ORG') # Test NER Again: In [17]: ner_test_doc = spacy_en(u"Rami Eid is studying at Stony Brook University in New York") In [18]: for ent in ner_test_doc.ents: ....: print(ent, ent.label, ent.label_) ....: (Rami Eid, 377, u'PERSON') (Stony Brook University, 380, u'ORG') # Noun Chunk In [19]: for np in test_doc.noun_chunks: ....: print(np) ....: Natural language processing a field computer science the interactions computers human languages programming computers large natural language corpora Challenges natural language processing natural language understanding formal, machine-readable logical forms language and machine perception, dialog systems some combination # Word Lemmatization In [20]: for token in test_doc[:20]: ....: print(token, token.lemma, token.lemma_) ....: ( , 518, u'\n') (Natural, 1854, u'natural') (language, 1374, u'language') (processing, 6038, u'processing') ((, 562, u'(') (NLP, 289623, u'nlp') (), 547, u')') (is, 536, u'be') (a, 506, u'a') (field, 2378, u'field') (of, 510, u'of') (computer, 1433, u'computer') (science, 1427, u'science') (,, 450, u',') (artificial, 5448, u'artificial') (intelligence, 2541, u'intelligence') (and, 512, u'and') (computational, 37658, u'computational') (linguistics, 398368, u'linguistic') (concerned, 3744, u'concern') # Word Vector Test and it seems something wrong In [21]: word_vector_test_doc =spacy_en(u"Apples and oranges are similar. Boots and hippos aren't.") In [22]: apples = word_vector_test_doc[0] In [23]: oranges = word_vector_test_doc[2] In [24]: apples.similarity(oranges) Out[24]: 0.0 |
spaCy models
The testing above is failed, cause since spaCy 1.7, the default english model not include the English glove vector model, need download it separately:
sudo python -m spacy download en_vectors_glove_md
Downloading en_vectors_glove_md-1.0.0/en_vectors_glove_md-1.0.0.tar.gz
Collecting https://github.com/explosion/spacy-models/releases/download/en_vectors_glove_md-1.0.0/en_vectors_glove_md-1.0.0.tar.gz
Downloading https://github.com/explosion/spacy-models/releases/download/en_vectors_glove_md-1.0.0/en_vectors_glove_md-1.0.0.tar.gz (762.3MB)
...
100% |████████████████████████████████| 762.3MB 5.5MB/s
Requirement already satisfied: spacy<2.0.0,>=0.101.0 in /usr/local/lib/python2.7/dist-packages (from en-vectors-glove-md==1.0.0)
Requirement already satisfied: numpy>=1.7 in /usr/local/lib/python2.7/dist-packages (from spacy<2.0.0,>=0.101.0->en-vectors-glove-md==1.0.0)
Requirement already satisfied: murmurhash<0.27,>=0.26 in /usr/local/lib/python2.7/dist-packages (from spacy<2.0.0,>=0.101.0->en-vectors-glove-md==1.0.0)
Requirement already satisfied: cymem<1.32,>=1.30 in /usr/local/lib/python2.7/dist-packages (from spacy<2.0.0,>=0.101.0->en-vectors-glove-md==1.0.0)
Requirement already satisfied: preshed<2.0.0,>=1.0.0 in /usr/local/lib/python2.7/dist-packages (from spacy<2.0.0,>=0.101.0->en-vectors-glove-md==1.0.0)
Requirement already satisfied: thinc<6.6.0,>=6.5.0 in /usr/local/lib/python2.7/dist-packages (from spacy<2.0.0,>=0.101.0->en-vectors-glove-md==1.0.0)
Requirement already satisfied: plac<1.0.0,>=0.9.6 in /usr/local/lib/python2.7/dist-packages (from spacy<2.0.0,>=0.101.0->en-vectors-glove-md==1.0.0)
Requirement already satisfied: six in /usr/local/lib/python2.7/dist-packages (from spacy<2.0.0,>=0.101.0->en-vectors-glove-md==1.0.0)
Requirement already satisfied: pathlib in /usr/local/lib/python2.7/dist-packages (from spacy<2.0.0,>=0.101.0->en-vectors-glove-md==1.0.0)
Requirement already satisfied: ujson>=1.35 in /usr/local/lib/python2.7/dist-packages (from spacy<2.0.0,>=0.101.0->en-vectors-glove-md==1.0.0)
Requirement already satisfied: dill<0.3,>=0.2 in /usr/local/lib/python2.7/dist-packages (from spacy<2.0.0,>=0.101.0->en-vectors-glove-md==1.0.0)
Requirement already satisfied: requests<3.0.0,>=2.13.0 in /usr/local/lib/python2.7/dist-packages (from spacy<2.0.0,>=0.101.0->en-vectors-glove-md==1.0.0)
Requirement already satisfied: regex==2017.4.5 in /usr/local/lib/python2.7/dist-packages (from spacy<2.0.0,>=0.101.0->en-vectors-glove-md==1.0.0)
Requirement already satisfied: ftfy<5.0.0,>=4.4.2 in /usr/local/lib/python2.7/dist-packages (from spacy<2.0.0,>=0.101.0->en-vectors-glove-md==1.0.0)
Requirement already satisfied: wrapt in /usr/local/lib/python2.7/dist-packages (from thinc<6.6.0,>=6.5.0->spacy<2.0.0,>=0.101.0->en-vectors-glove-md==1.0.0)
Requirement already satisfied: tqdm<5.0.0,>=4.10.0 in /usr/local/lib/python2.7/dist-packages (from thinc<6.6.0,>=6.5.0->spacy<2.0.0,>=0.101.0->en-vectors-glove-md==1.0.0)
Requirement already satisfied: cytoolz<0.9,>=0.8 in /usr/local/lib/python2.7/dist-packages (from thinc<6.6.0,>=6.5.0->spacy<2.0.0,>=0.101.0->en-vectors-glove-md==1.0.0)
Requirement already satisfied: termcolor in /usr/local/lib/python2.7/dist-packages (from thinc<6.6.0,>=6.5.0->spacy<2.0.0,>=0.101.0->en-vectors-glove-md==1.0.0)
Requirement already satisfied: idna<2.6,>=2.5 in /usr/local/lib/python2.7/dist-packages (from requests<3.0.0,>=2.13.0->spacy<2.0.0,>=0.101.0->en-vectors-glove-md==1.0.0)
Requirement already satisfied: urllib3<1.22,>=1.21.1 in /usr/local/lib/python2.7/dist-packages (from requests<3.0.0,>=2.13.0->spacy<2.0.0,>=0.101.0->en-vectors-glove-md==1.0.0)
Requirement already satisfied: chardet<3.1.0,>=3.0.2 in /usr/local/lib/python2.7/dist-packages (from requests<3.0.0,>=2.13.0->spacy<2.0.0,>=0.101.0->en-vectors-glove-md==1.0.0)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python2.7/dist-packages (from requests<3.0.0,>=2.13.0->spacy<2.0.0,>=0.101.0->en-vectors-glove-md==1.0.0)
Requirement already satisfied: html5lib in /usr/local/lib/python2.7/dist-packages (from ftfy<5.0.0,>=4.4.2->spacy<2.0.0,>=0.101.0->en-vectors-glove-md==1.0.0)
Requirement already satisfied: wcwidth in /usr/local/lib/python2.7/dist-packages (from ftfy<5.0.0,>=4.4.2->spacy<2.0.0,>=0.101.0->en-vectors-glove-md==1.0.0)
Requirement already satisfied: toolz>=0.8.0 in /usr/local/lib/python2.7/dist-packages (from cytoolz<0.9,>=0.8->thinc<6.6.0,>=6.5.0->spacy<2.0.0,>=0.101.0->en-vectors-glove-md==1.0.0)
Requirement already satisfied: setuptools>=18.5 in /usr/local/lib/python2.7/dist-packages (from html5lib->ftfy<5.0.0,>=4.4.2->spacy<2.0.0,>=0.101.0->en-vectors-glove-md==1.0.0)
Requirement already satisfied: webencodings in /usr/local/lib/python2.7/dist-packages (from html5lib->ftfy<5.0.0,>=4.4.2->spacy<2.0.0,>=0.101.0->en-vectors-glove-md==1.0.0)
Installing collected packages: en-vectors-glove-md
Running setup.py install for en-vectors-glove-md ... done
Successfully installed en-vectors-glove-md-1.0.0
Linking successful
/usr/local/lib/python2.7/dist-packages/en_vectors_glove_md/en_vectors_glove_md-1.0.0
-->
/usr/local/lib/python2.7/dist-packages/spacy/data/en_vectors_glove_md
You can now load the model via spacy.load('en_vectors_glove_md').
Now you can load the English glove vector model and test the by it:
In [1]: import spacy In [2]: spacy_en = spacy.load('en_vectors_glove_md') In [3]: word_vector_test_doc =spacy_en(u"Apples and oranges are similar. Boots and hippos aren't.") In [4]: apples = word_vector_test_doc[0] In [5]: oranges = word_vector_test_doc[2] In [6]: apples.similarity(oranges) Out[6]: 0.77809414836023805 In [7]: boots = word_vector_test_doc[6] In [8]: hippos = word_vector_test_doc[8] In [9]: boots.similarity(hippos) Out[9]: 0.038474555379008429 |
The available spaCy models is listed below, you can download them by your needs: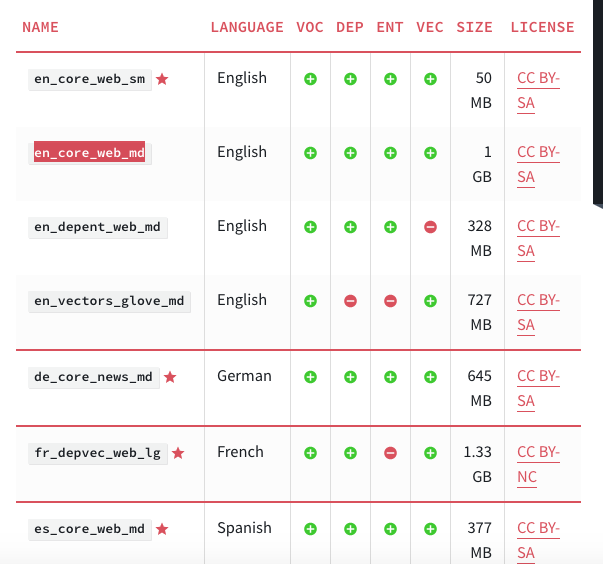
Reference:
Posted by TextProcessing