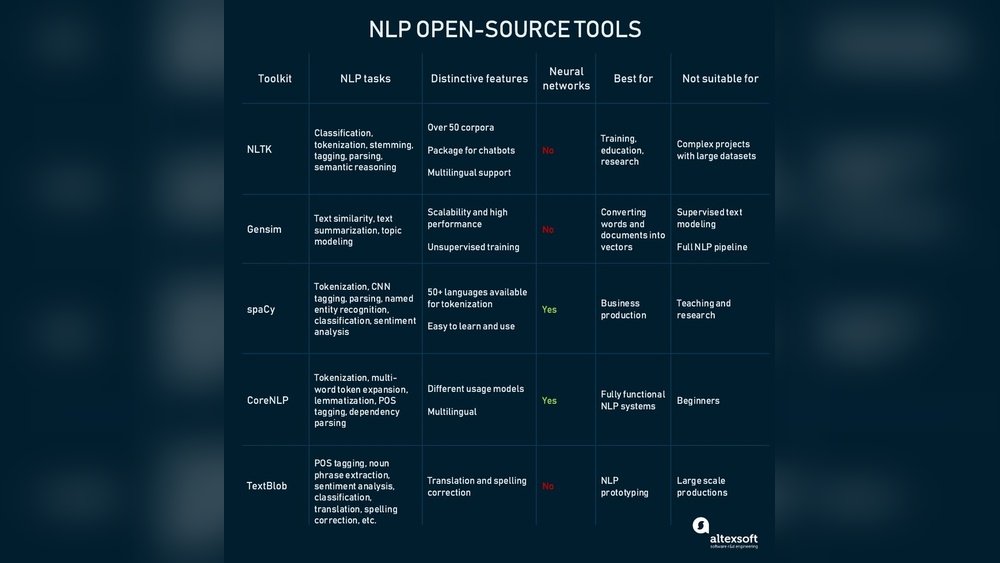
If you work with text data, you know how tricky it can be to analyze words in their many forms. That’s where PyStemmer comes in—a powerful open source project designed to simplify text processing by reducing words to their root forms.
Imagine instantly cutting through the noise of suffixes and endings to reveal the core meaning of any word. Whether you’re building search engines, chatbots, or data analysis tools, PyStemmer gives you a reliable, efficient way to handle language like a pro.
Keep reading to discover how this tool can transform your text processing tasks and why it’s becoming a favorite among developers worldwide.
What Is Pystemmer
PyStemmer is an open source project that helps process text efficiently. It focuses on stemming, which means reducing words to their base form. This makes text analysis easier and faster. PyStemmer is widely used in natural language processing tasks to improve search, indexing, and text mining.
The project offers a simple interface to powerful stemming algorithms. It removes common endings from words, making different forms of the same word look alike. This helps computers understand the core meaning without being confused by word variations.
Core Features
PyStemmer provides fast and reliable stemming for many languages. It uses well-tested algorithms to ensure quality results. The library is easy to install and integrate with Python projects. It supports batch processing, allowing users to stem large amounts of text efficiently. The tool is lightweight and requires minimal resources, making it suitable for various applications.
Supported Languages
PyStemmer supports over 15 languages, including English, Spanish, French, and German. It covers a broad range of European and non-European languages. This wide support helps developers work on multilingual projects without switching tools. Each language uses specific rules to handle unique word structures. The project continues to add more languages based on community needs.
Stemming Algorithms
PyStemmer uses the Snowball stemming algorithms, known for their accuracy. Snowball is a collection of language-specific algorithms designed to remove common suffixes. These algorithms balance between precision and speed. They avoid over-stemming, which can distort the original meaning. The use of Snowball ensures consistent and meaningful stems across different texts.
Installing Pystemmer
Installing PyStemmer is a key step to start using this open source text processing tool. It allows you to apply fast and reliable stemming algorithms in your Python projects. The installation process is straightforward and can be done using Python’s package manager.
This section explains how to install PyStemmer using pip. It also covers system requirements and common issues you may face during installation.
Using Pip
Open your command prompt or terminal. Type pip install PyStemmer and press Enter. Pip downloads and installs the package automatically. Make sure you have Python and pip already installed on your system. After installation, test it by running python -c "import Stemmer". No errors mean the installation was successful.
System Requirements
PyStemmer supports Python 3.6 and above. It works on Windows, macOS, and Linux. You need a working Python environment with pip installed. The package size is small, so it does not require much disk space. Ensure your Python version is up to date for best results.
Troubleshooting Installation
Errors can happen if Python or pip is not installed properly. Check your Python version by running python --version. Upgrade pip with pip install --upgrade pip. On some systems, use pip3 instead of pip. If permission errors occur, try running the command with sudo on macOS/Linux or as an administrator on Windows.
Key Functions In Pystemmer
PyStemmer offers powerful tools for text processing tasks. Its key functions simplify handling and transforming words for analysis. The project focuses on stemming, batch processing, and customization. These features make PyStemmer a flexible option for developers.
Stemming Words
Stemming reduces words to their base form. PyStemmer uses efficient algorithms for this task. It removes common endings like “ing” or “ed.” This helps group similar words in text analysis. Stemming improves search accuracy and text mining results.
Batch Processing
PyStemmer can process many words at once. This saves time during large text analysis projects. Users can input lists or entire documents. The tool quickly stems every word in the batch. Batch processing boosts performance and productivity.
Customization Options
PyStemmer allows users to customize the stemming process. It supports different languages and algorithms. Users can choose stemmers that fit their needs best. This flexibility helps apply PyStemmer in various contexts. Customization ensures better results for specific tasks.

Credit: lrec-conf.org
Integrating Pystemmer In Nlp Projects
Integrating PyStemmer into your natural language processing projects can simplify many common text handling tasks. PyStemmer uses efficient algorithms to reduce words to their base forms. This helps software understand text better by focusing on the core meaning of words. The tool works well with different languages and is easy to add to Python projects. Below are key ways to use PyStemmer for better text processing results.
Preprocessing Text Data
PyStemmer makes text preprocessing faster and more effective. It removes common word endings, turning words like “running” into “run.” This reduces the total number of unique words in your data. Smaller vocabulary means simpler models and faster training. Stemming also helps handle typos and word variations in your dataset. Preprocessed text feeds cleaner data to your NLP pipeline.
Improving Search Accuracy
Search systems benefit from PyStemmer by matching word stems, not just exact words. For example, a search for “connect” can find “connected” and “connecting.” This broadens search results without losing relevance. Users find what they need quicker. PyStemmer supports multiple languages, making it useful in global search applications. It boosts user satisfaction by understanding word variations.
Enhancing Text Classification
Text classification models perform better with stemmed input. PyStemmer reduces noise from word forms that carry the same meaning. This helps classifiers focus on key features in the text. The result is higher accuracy in tasks like spam detection or sentiment analysis. PyStemmer’s speed means it fits well into real-time systems. Its simplicity makes it a valuable tool for developers.
Comparison With Other Stemming Libraries
Comparing Pystemmer with other stemming libraries helps understand its strengths and limits. This comparison covers performance, algorithm design, and use cases. It guides developers to pick the best tool for their projects.
Performance Benchmarks
Pystemmer often runs faster than many other stemming libraries. It uses efficient code optimized for speed. Memory use is also low, making it suitable for large datasets. In tests, Pystemmer processes thousands of words per second. This speed is crucial for real-time text analysis.
Algorithm Differences
Pystemmer relies on Snowball algorithms known for accuracy. Other libraries may use simpler, rule-based methods. Snowball balances between aggressive and light stemming. This means it reduces words well without losing meaning. Some libraries focus only on English, but Pystemmer supports multiple languages. This broad support makes it flexible for global projects.
Use Case Suitability
Pystemmer works well for search engines and text mining. It handles various languages, helping in multilingual environments. Some libraries fit better for very specific tasks or languages. Pystemmer suits projects needing both speed and accuracy. For educational tools or small projects, simpler stemmers might be enough.

Credit: www.sciencedirect.com
Contributing To Pystemmer
Contributing to PyStemmer offers a chance to improve a key tool in text processing. It helps the community by making the software better and more useful. Anyone interested in natural language processing can join and share ideas or code. The project thrives on collaboration and welcomes new contributors.
Accessing The Github Repository
The PyStemmer code is hosted on GitHub. You can visit the repository to explore the source files. Fork the project to create your own copy for changes. Use Git to clone the repository to your local machine. This setup lets you test and develop features easily.
Submitting Issues And Pull Requests
Found a bug or want to suggest a feature? Open an issue in the repository. Provide clear details to help maintainers understand the problem. To fix issues or add improvements, create a pull request. Follow the repository’s template and instructions for smooth review.
Community Guidelines
PyStemmer values respect and clear communication in its community. Read the code of conduct before contributing. Keep discussions polite and focused on the project. Follow coding standards and write clean, documented code. These practices help maintain a welcoming environment for all.
Boosting Nlp Skills With Pystemmer
Boosting your Natural Language Processing (NLP) skills with PyStemmer offers a practical way to handle text data. PyStemmer uses efficient algorithms to reduce words to their root forms. This process, called stemming, helps simplify text analysis and improves machine learning models.
Using PyStemmer, beginners and experts can explore the basics of text preprocessing. It supports multiple languages and is easy to integrate into Python projects. This makes it a valuable tool for anyone wanting to understand how words relate to each other.
Hands-on Examples
Start by installing PyStemmer with a simple command. Import the library and create a stemmer for your language. Pass words to the stemmer to get their root forms. For instance, “running,” “runner,” and “runs” all become “run.”
Try stemming a list of words to see how the library handles different endings. Experiment with different languages to notice variations. This hands-on practice helps solidify your understanding of stemming in NLP.
Building Custom Pipelines
Combine PyStemmer with other NLP tools to build custom pipelines. You can tokenize text, remove stop words, and then stem the tokens. This sequence cleans and simplifies text for further analysis.
Custom pipelines help manage large datasets efficiently. They prepare data for tasks like sentiment analysis or topic modeling. PyStemmer fits well as a preprocessing step in these pipelines.
Learning Resources
Explore PyStemmer’s official documentation for clear usage examples. Check out GitHub repositories for community projects and code samples. Online tutorials and forums offer practical advice and troubleshooting tips.
Practice by working on small projects or datasets. Learning by doing helps retain knowledge and improves your NLP skills steadily. PyStemmer is a great starting point for anyone new to text processing.

Credit: github.com
Real-world Applications
PyStemmer plays a key role in many practical text processing tasks. It helps software understand words by reducing them to their basic forms. This ability allows computers to handle language more effectively across various fields.
Its real-world uses show how important stemming is. Many popular technologies rely on PyStemmer to process and analyze large amounts of text quickly and accurately.
Search Engines
Search engines use PyStemmer to improve query results. It breaks down words to their root forms. This allows the engine to match different word forms in documents. For example, “running” and “run” are treated the same. This process helps users find relevant information faster and with less effort.
Sentiment Analysis
PyStemmer supports sentiment analysis by simplifying words before analysis. It reduces variations of words to a common base. This helps the system understand the true meaning behind user opinions. Businesses use this to gauge customer feelings from reviews or social media posts. Accurate stemming improves the quality of sentiment detection and decision-making.
Chatbots And Virtual Assistants
Chatbots and virtual assistants rely on PyStemmer for better language understanding. It helps these systems grasp user intent despite word variations. By stemming words, bots can respond more accurately to questions. This leads to smoother and more natural conversations. Users get faster and more helpful responses.
Frequently Asked Questions
What Is Pystemmer?
PyStemmer is a Python library that efficiently computes the stemmed form of words. It removes common morphological endings to find the base linguistic form. It uses Snowball stemmers for fast and accurate text processing in natural language tasks.
What Is The Open Source Text Processing Project Pystemmer?
Pystemmer is a Python library that uses Snowball stemmers for word stemming. It helps find the root form of words by removing common endings. This makes text analysis easier and faster.
How Does Pystemmer Improve Natural Language Processing?
Pystemmer simplifies words to their base form, reducing variations in text. This helps machines understand and process language more accurately. It works well for search, classification, and text mining.
Which Languages Does Pystemmer Support For Stemming?
Pystemmer supports many languages, including English, French, Spanish, and German. It uses Snowball algorithms tailored to each language’s rules. This makes it versatile for global text processing projects.
How Can Developers Integrate Pystemmer In Python Projects?
Developers can install Pystemmer via pip and import it into their code. It provides easy-to-use functions for stemming words in text data. Integration requires minimal coding and improves text handling efficiently.
Conclusion
Pystemmer offers a simple way to handle word stems in text. It helps reduce words to their root forms quickly. This makes text analysis cleaner and more efficient. The open-source nature allows anyone to use and improve it. Developers and learners can benefit from its easy access and clear results.
Try Pystemmer to simplify your text processing tasks today.